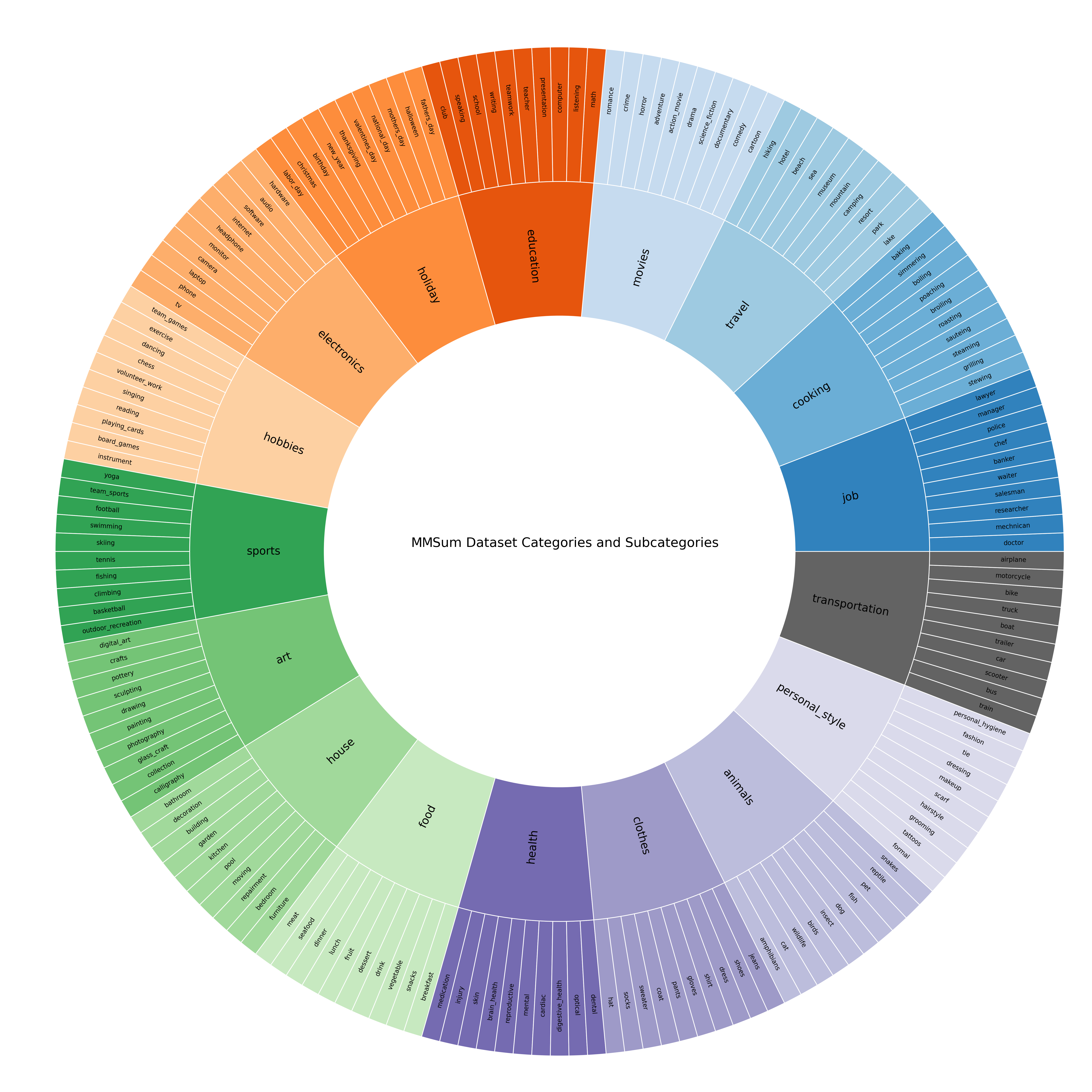
The 17 main categories of the MMSum dataset, where each main category contains 10 subcategories, resulting in 170 subcategories in total.
Abstract
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MMSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MMSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments.
MMSum Data Statistics
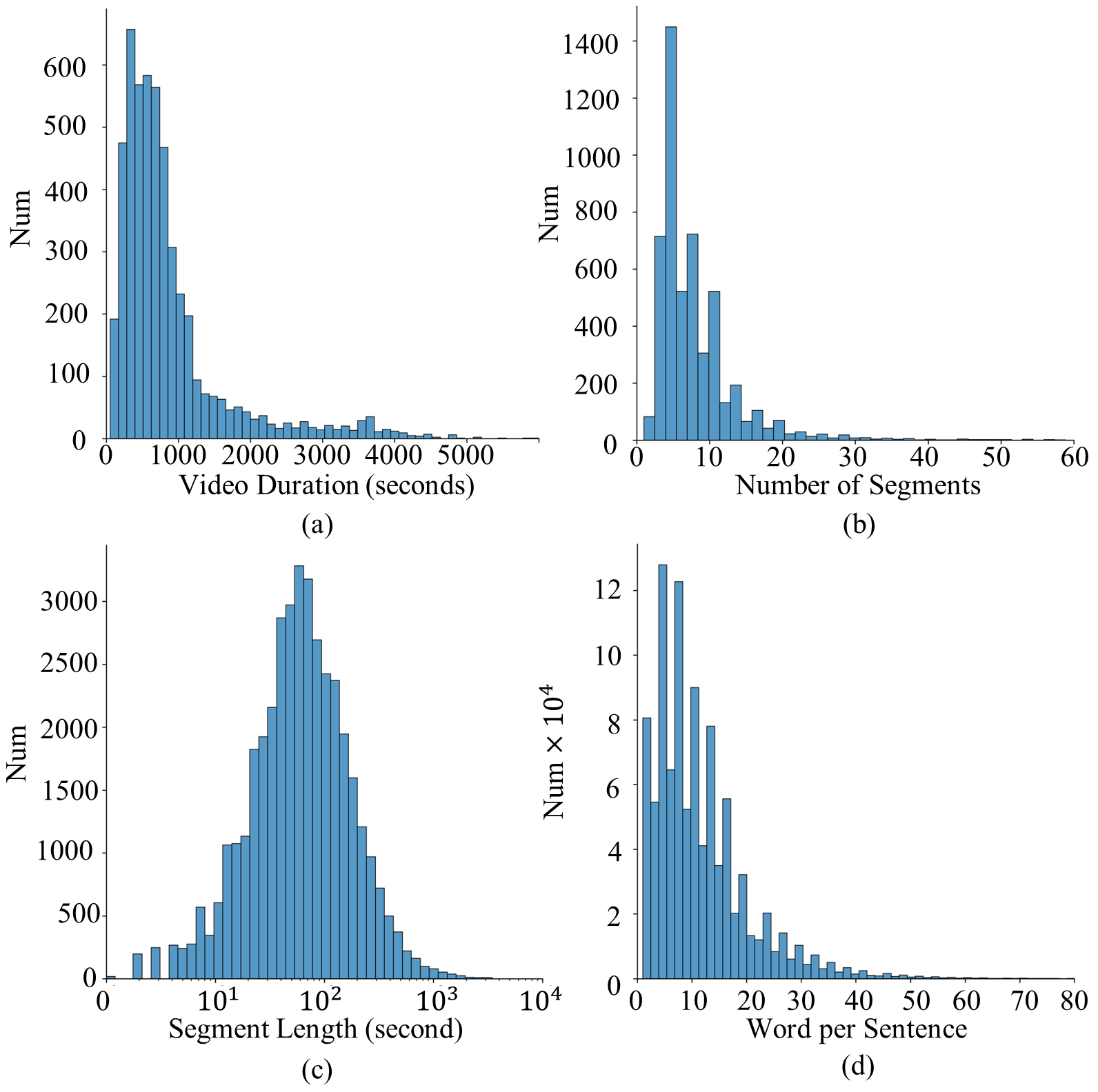
The statistics of the MMSum dataset, which show the distribution of (a) video duration; (b) number of segments per video; (c) segment duration; (d) number of words per sentence.
Task Comparison
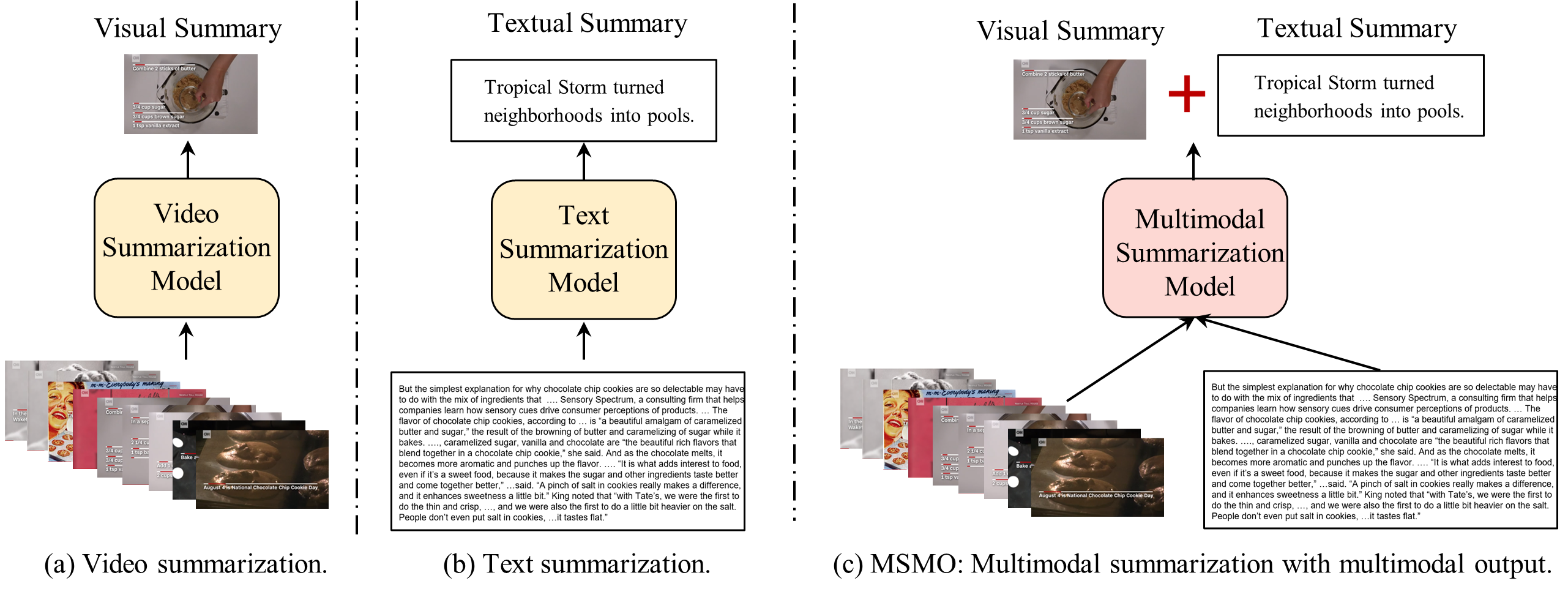
Task comparison of traditional video summarization, text summarization, and the new MSMO (multimodal summarization with multimodal output) task.
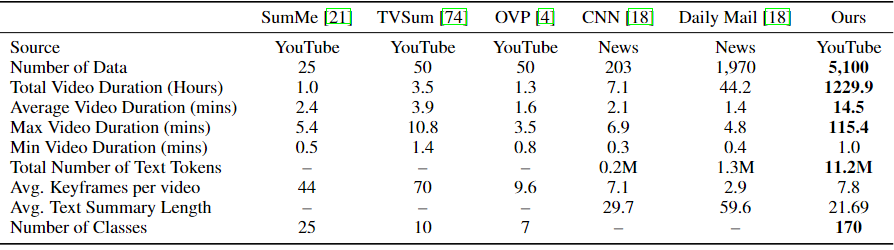
Comparison with existing video summarization and multimodal summarization datasets.
MMSum Benchmark Pipeline
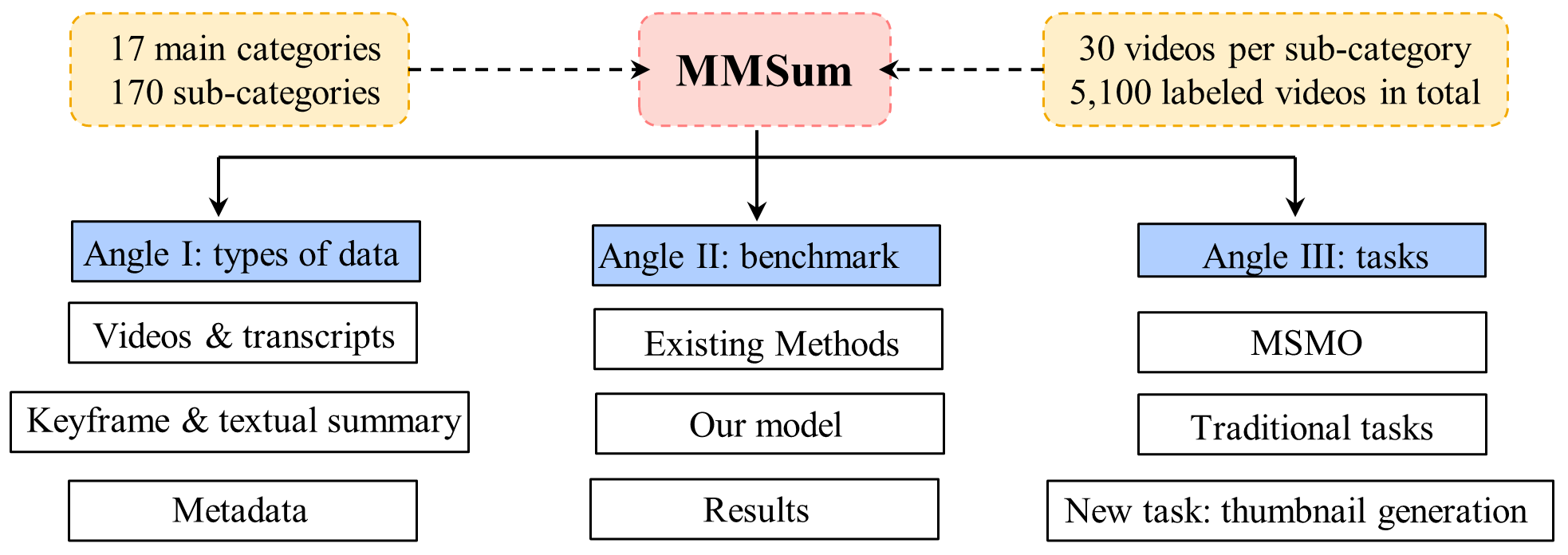
The design of the proposed MMSum dataset is driven by research and application needs.
Comparison of different summarization tasks and datasets
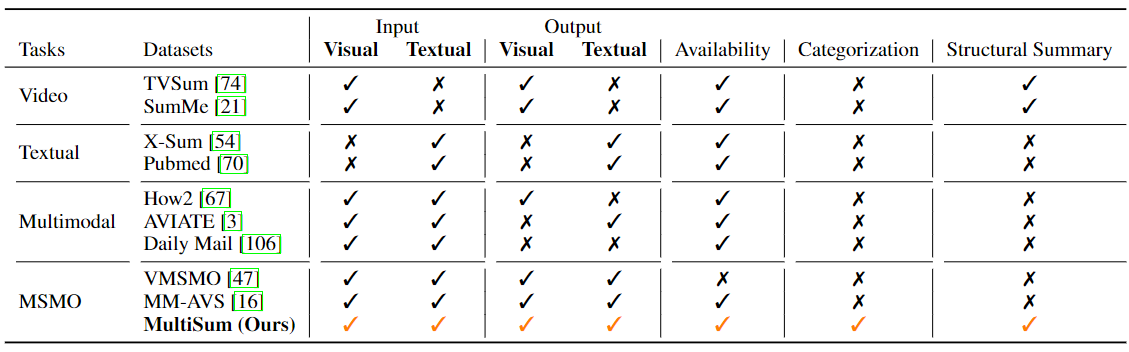
Comparison of the modality of different summarization tasks and datasets, where MSMO is short for Multimodal Summarization with Multimodal Output. The major difference between traditional multimodal summarization and MSMO is that traditional multimodal summarization still outputs a single-modality summary, while MSMO outputs both modalities' summaries.
Thumbnail Generation
One direct and practical application of the MSMO task is to automatically generate thumbnails for a given video, which has become increasingly valuable in various real-world applications. With the exponential growth of online videos, effective and efficient methods are required to extract visually appealing and informative thumbnail representations. In addition, many author-generated thumbnails involve words or titles that describe the whole video to attract more users. In the context of online platforms, such as video-sharing websites or social media platforms, compelling thumbnails can significantly impact user engagement, content discoverability, and overall user experience. The benefits of automated thumbnail generation extend beyond user engagement and content discoverability. In e-commerce, for instance, thumbnails can play a vital role in attracting potential buyers by effectively showcasing products or services. Similarly, in video editing workflows, quick and accurate thumbnail generation can aid content creators in managing and organizing large video libraries efficiently.